기계 학습에서 감독 학습은 가장 일반적으로 사용되는 기계 학습 알고리즘입니다.
과거의 알려진 예를 기반으로 일반화된 모델을 생성하여 의사 결정 프로세스를 자동화하는 방법입니다.
분류
여러 사전 정의된 가능한 클래스 이름 중 하나 예측
회귀
연속 숫자 예측
분류 대 회귀?
초기값이 연속성을 가지는지 물어보면 분류와 회귀를 쉽게 구분할 수 있습니다.
회사원 A씨의 월급이 400만원이 될 것이라고 예측해야 하는데 400만원을 예측했다고? 큰 차이 없음 (돌려 주다)
웹사이트가 어떤 언어인지 감지 영어 vs 한국어 vs 프랑스어 등 둘 중 하나 (분류)
일반화
지도 학습에서 훈련 데이터로 훈련된 모델이 훈련 데이터와 동일한 속성을 가지고 있으면 이전에 본 적이 없는 새로운 데이터가 주어져도 정확한 예측을 할 것으로 기대됩니다.
새로운 데이터에 대해 정확한 예측을 할 수 있는 경우 교육 데이터 세트에서 테스트 데이터 세트로 전송할 수 있습니다. 일반화 그랬어야 했어요.
과적합
사용 가능한 모든 정보를 사용하여 지나치게 복잡한 모델을 만들면 과적합(overfitted)되었다고 합니다.
이는 일반적으로 모델이 훈련 세트의 모든 샘플에 너무 가깝게 맞아 새 데이터로 일반화하기 어려울 때 발생합니다.
장비 부족
오버피팅과 달리 이는 지나치게 단순한 모델을 선택하는 것을 의미합니다.
과소적합의 주요 단점은 데이터의 측면과 다양성을 포착할 수 없다는 것입니다.
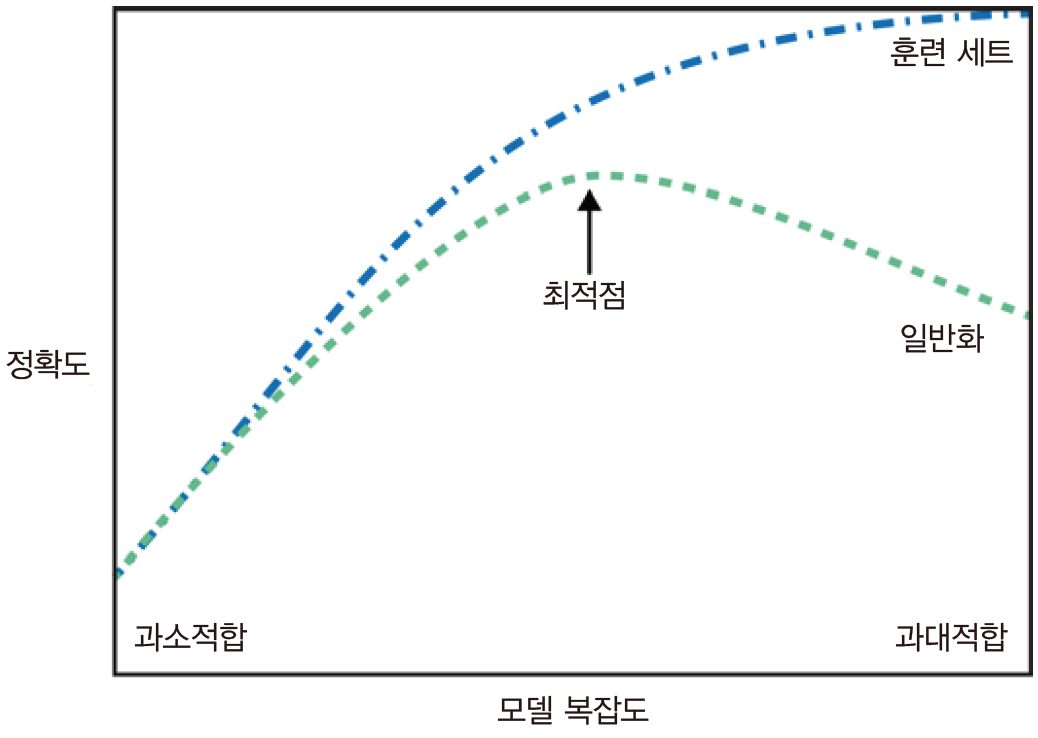
마지막으로 우리의 궁극적인 목표는 일반화 성능이 최대화되는 스윗 스팟에 있는 모델입니다!
감독 학습 알고리즘
1. k-최근접 이웃
• 가장 간단한 기계 학습 알고리즘입니다.
• 학습 데이터 세트에서 찾은 가장 가까운 “가장 가까운 이웃”이 예측에 사용되며 이 학습 데이터 포인트는 단순히 예측 값으로 반환됩니다.
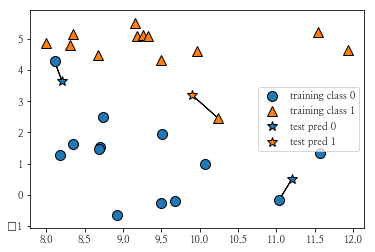
2개의 클래스가 있는 무작위 Forge 데이터 세트의 산점도, 3개의 데이터 포인트(★)를 추가하고 추가된 포인트에 가장 가까운 훈련 데이터 포인트를 연결합니다.
물론 가장 가까운 이웃 대신 임의로 k를 선택할 수도 있습니다.
이 시점에서 라벨을 결정하기 위한 투표가 진행됩니다.
“클래스 0의 테스트 포인트에 대한 이웃은 몇 개입니까? 1반에는 몇 명의 이웃이 있습니까?”
이후 더 많은 이웃과 함께하는 라벨 수업
즉, k-최근접 이웃 대다수의 클래스가 레이블이 됩니다
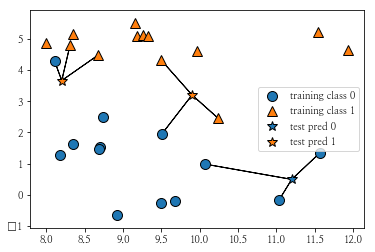
좌측 상단의 테스트 포인트를 보면 Class 0 in 1 – Nearest Neighbor로 분류되었던 포인트가 Class 1로 분류된 것을 확인할 수 있습니다.
1반 이웃이 많아져서 결국 이름이 바뀌었네요!
KNeighborsClassifier 분석
xy 평면에 가능한 모든 테스트 포인트의 예측을 플로팅한 후,
클래스 0과 클래스 1로 레이블이 지정된 영역의 결정 경계를 고려해 보겠습니다.
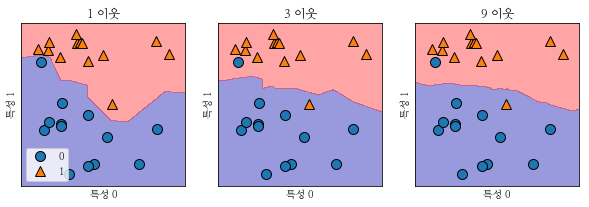
하나의 이웃을 선택했을 때보다 이웃의 수가 증가했을 때 결정 경계가 훨씬 더 매끄럽다는 것을 알 수 있습니다.
부드러운 테두리 더 간단한 모델즉, 이웃을 적게 사용하면 모델의 복잡도가 증가하고 많이 사용하면 복잡도가 감소합니다.
k-최근접 이웃 회귀
k-최근접 이웃 알고리즘은 회귀 분석에도 사용됩니다.
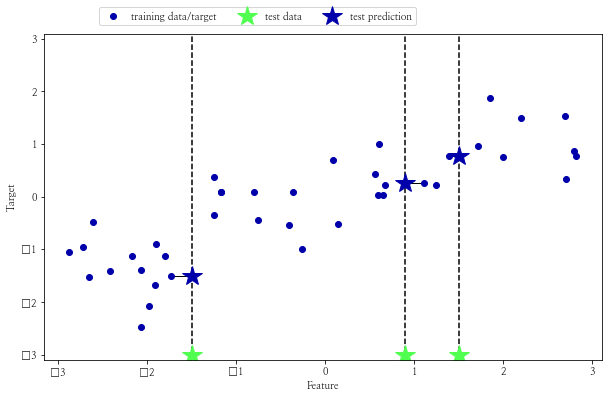
임의 웨이브 데이터 세트에 대한 단일 이웃 최근 이웃 알고리즘입니다.
가장 가까운 이웃만 사용하는 경우 예측은 단순히 가장 가까운 이웃 대상 값으로 출력됩니다.
다시 말하지만 회귀 분석은 둘 이상의 이웃에 대해 수행할 수 있습니다. 이웃 간의 평균이 예측은 됩니다.
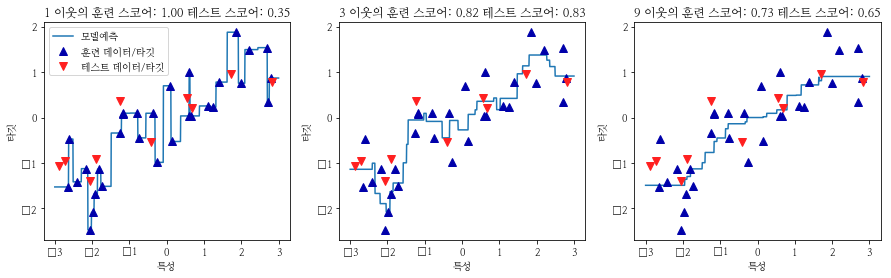
하나의 이웃만 사용하는 경우 훈련 세트의 각 데이터 포인트는 예측에 매우 큰 기여를 하므로 예측이 모든 훈련 데이터 포인트를 통과합니다. 이것은 매우 불안정한 예측으로 이어집니다
많은 이웃을 사용하면 교육 데이터에 잘 맞지 않을 수 있지만 보다 강력한 예측을 제공합니다.
찬반 양론 및 매개 변수
일반적으로 KNeighbors 분류기에는 두 가지 중요한 매개변수가 있습니다.
1. 데이터 포인트 간의 거리 측정 방법
2. 이웃 수
k-NN의 장점은 매우 이해하기 쉬운 모델이며 많은 튜닝 없이 잘 작동하는 경우가 많다는 것입니다.
가장 가까운 이웃 모델은 일반적으로 구축 속도가 매우 빠르지만 훈련 세트가 매우 크면 예측 속도가 느립니다.
이 알고리즘을 사용할 때 데이터 전처리 과정이 매우 중요하고 수백 개 이상의 피처가 있는 데이터셋에는 잘 작동하지 않아 실제로 잘 사용되지 않는다.
다음 게시물은 이러한 k-최근접 이웃을 개선하는 선형 모델 알고리즘과 함께 올 것입니다